


深圳推广公司介绍谷歌解释了Robots文件阻止页面
发布时间:2019-07-11 12:32 点击量:次
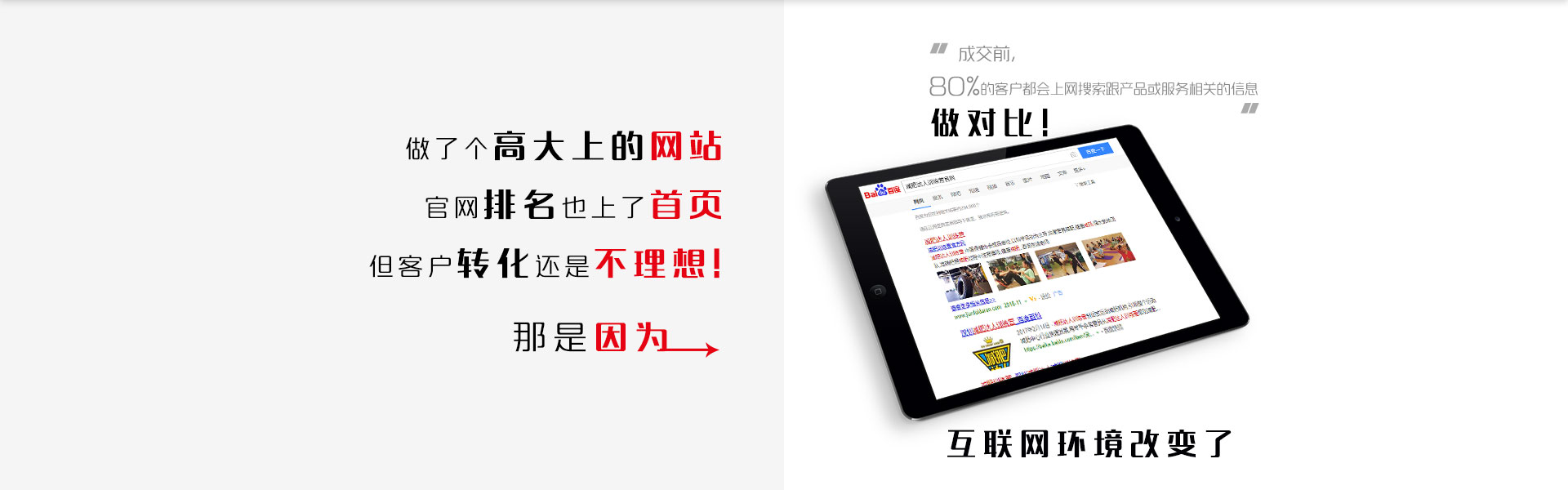
深圳推广公司介绍谷歌解释了Robots文件阻止页面排名的方式

谷歌的约翰·缪勒最近解释了如何确定robots.txt阻止的网页的查询相关性。
它已被指出,谷歌仍然会遭到robots.txt阻止索引页。但谷歌如何知道对这些页面进行排名的查询类型?
这就是昨天的谷歌网站管理员中心环聊中出现的问题:
“现在每个人都在谈论用户意图。如果某个网页被robots.txt屏蔽,并且正在排名,谷歌会如何确定与网页内容相关的查询相关性?
作为回应,穆勒表示,如果内容被阻止,谷歌显然无法查看内容。
所以谷歌所做的就是找到其他方法来将网址与其他网址进行比较,当被robots.txt阻止时,这肯定会更难。
在大多数情况下,谷歌会优先编制网站其他网页的索引,这些网页更易于访问且不会被阻止抓取。
如果谷歌认为有价值的话,有时被robots.txt屏蔽的网页会在搜索结果中排名。这是由指向页面的链接决定的。
那么谷歌如何找出如何对被阻止的网页进行排名呢?答案归结为链接。
最终,用robots.txt阻止内容并不是明智之举,并希望谷歌知道如何处理它。
但是,如果您碰巧有被robots.txt阻止的内容,谷歌会尽力弄清楚如何对其进行排名。
本文标签: 深圳推广公司

推荐文章
- 网络推广公司如何设置文04-27
- 网络推广公司做伪原创的04-27
- 网络推广公司seo推广需先11-19
- 网络推广公司如何做好网11-15
- 网络推广公司如何做好网11-15
- 网络推广公司不同的链接11-05
- 网络推广公司SEO老手和S11-05
- 深圳推广公司介绍网站优09-18
- 深圳推广公司细说网站优09-18
- SEO入门到精通需要这5个步08-13
- 哪些类型的网站需要SE008-07
- 深圳推广公司介绍鼓励客07-25
- 深圳推广公司介绍鼓励客07-25
- 深圳推广公司介绍选择S07-25
- 深圳推广公司介绍选择S07-24
- 深圳推广公司介绍为什么07-24
- 深圳推广公司介绍为什么07-24
- 深圳推广公司介绍为什么07-23
点击排行
- 深圳推广公司介绍网络推07-02
- 国内工业互联网面临三大12-29
- 推特删除了向推文添加精06-24
- 网络推广好做吗?带你梳12-20
- 如何做好网络营销推广?12-20
- 年底做网络推广的优势,12-20
- 企业建站用什么CMS系统比12-20
- 亚马逊SEO现在比品牌谷歌03-26
- 所有谷歌广告归因报告都04-02
- 大学男生靠做PPT净赚30万,12-20
- 微信朋友圈营销怎么做12-20
- 谷歌允许将YouTube直播流作06-21
- 平面设计配色原理!“知12-20
- 网络推广的前期准备工作12-20
最新文章
- 网络推广公司如何设置文04-27
- 网络推广公司做伪原创的04-27
- 网络推广公司做好网站S04-27
- 网络推广公司对文章标题04-27
- 网站推广公司对文章字数04-27
- 网络推广公司对外链的搭01-15
- 网络推广公司介绍网站优01-15
- 网络推广公司对网站首页01-08
- 网络推广公司详解企业网01-03
- 网络推广公司介绍关于旅01-02
- 网络推广公司对于旅游网12-31
- 网络推广公司介绍如何持12-31
- 网络推广公司介绍吸引用12-30
- 网络推广公司细说网站推12-30




